CIFAR-10 - Keras¶
1. Loading the dataset¶
import numpy as np
from keras.datasets import cifar10
from keras.utils.np_utils import to_categorical
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
Examining the dataset¶
print("Shape of training data:")
print(X_train.shape)
print(y_train.shape)
print("Shape of test data:")
print(X_test.shape)
print(y_test.shape)
We have 50000 training and 10000 test images in the dataset. The images have a structure of (32,32,3) which correspond to (width, height, RGB).
For each image there is a corresponding label, which is a class index.
import matplotlib.pyplot as plt
cifar_classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print('Example training images and their labels: ' + str([x[0] for x in y_train[0:5]]))
print('Corresponding classes for the labels: ' + str([cifar_classes[x[0]] for x in y_train[0:5]]))
f, axarr = plt.subplots(1, 5)
f.set_size_inches(16, 6)
for i in range(5):
img = X_train[i]
axarr[i].imshow(img)
plt.show()

Preparing the dataset¶
First we are going to use a Multilayer Perceptron to classify our images.
Instead of class indices we will use one-hot encoded vectors to represent the labels of the samples. We also need to vectorize the images, since the MLP will take a 3072-dimensional vector as the input. When working with images, a simple way to normalize our data is to fit it within the 0 to 1 range.
# Transform label indices to one-hot encoded vectors
y_train = to_categorical(y_train, num_classes=10)
y_test = to_categorical(y_test, num_classes=10)
# Transform images from (32,32,3) to 3072-dimensional vectors (32*32*3)
X_train = np.reshape(X_train,(50000,3072))
X_test = np.reshape(X_test,(10000,3072))
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# Normalization of pixel values (to [0-1] range)
X_train /= 255
X_test /= 255
2. MLP classifier¶
The MLPs are capable of modelling complex classification problems which are typically not linearly separable.
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.optimizers import SGD
model = Sequential()
model.add(Dense(256, activation='relu', input_dim=3072))
model.add(Dense(256, activation='relu'))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd,
loss='categorical_crossentropy',
metrics=['accuracy'])
Training the MLP¶
Let's train our model now! We will store the training loss values and metrics in a history object, so we can visualize the training process later.
We are going to train the model for 15 epochs, using a batch size of 32 and a validation split of 0.2. The latter means that 20% of our training data will be used as validation samples (in practice however it is advised to separate the validation data from the training data altogether).
history = model.fit(X_train,y_train, epochs=15, batch_size=32, verbose=2, validation_split=0.2)
With this simple function we will be able to plot our training history.
def plotLosses(history):
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
plotLosses(history)

Evaluating the MLP¶
To get a measure of our model's performance we need to evaluate it using the test samples:
score = model.evaluate(X_test, y_test, batch_size=128, verbose=0)
print(model.metrics_names)
print(score)
2. CNN classifier¶
So far, we have not exploited that we are working with images. By using Convolutional Neural Networks, we can take advantage of the special structure of the inputs. Convolutions are translation invariant, and this makes them especially well suited for processing images.
Preparing the dataset¶
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
y_train = to_categorical(y_train, num_classes=10)
y_test = to_categorical(y_test, num_classes=10)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
print("Shape of training data:")
print(X_train.shape)
print(y_train.shape)
print("Shape of test data:")
print(X_test.shape)
print(y_test.shape)
Creating CNN model¶
We will use two convolutional layers, each with 32 filters a kernel size of (3,3) and ReLU activation function.
from keras.layers import Dense, Flatten
from keras.layers import Conv2D, MaxPooling2D
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer=sgd)
Training the CNN¶
history = model.fit(X_train, y_train, batch_size=32, epochs=15, verbose=2, validation_split=0.2)
plotLosses(history)

Evaluating the CNN¶
score = model.evaluate(X_test, y_test, batch_size=128, verbose=0)
print(model.metrics_names)
print(score)
As we can see, the CNN reached significantly higher accuracy than the MLP classifier, but overfitting occured during the training of our model. To avoid this, the use of some regularization techniques would be advised.
3. Regularization¶
In most cases, larger models have a tendency to overfit training data. While getting good performance on the training set, they will perform poorly on the test set. Regularization methods are used to prevent overfitting, making these larger models generalize better.
3.1 Dropout¶
Dropout works on a neural network layer by masking a random subset of its outputs (zeroing them) for every input with probability p and scaling up the rest of the outputs by 1/(1 - p).
Dropout is normally used during training. Masking prevents gradient backpropagation through the masked outputs. The method thus selects a random subset of the neural network to train on any particular example. This can be thought of as training a model ensemble to solve the task, with the individual models sharing parameters.
At test time, p is set to zero. This can be interpreted as averaging the outputs of the ensemble models. Because of the scaling, the expected layer outputs are the same during training and testing.
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# Dropout layer added here
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
# Dropout layer added here
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer=sgd)
Training the CNN which now contains dropout layers¶
history = model.fit(X_train, y_train, batch_size=32, epochs=15, verbose=2, validation_split=0.2)
plotLosses(history)

3.2 Batch normalization¶
Batch Normalization works by normalizing layer outputs to a running mean and variance. This speeds up training and improves the final performance of the model. The running statistics are fixed at test time.
While batch normalization works as a regularizer, it also benefits smaller models.
from keras.layers import Dense, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3)))
# Batch normalization layer added here
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256))
# Batch normalization layer added here
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer=sgd)
history = model.fit(X_train, y_train, batch_size=32, epochs=15, verbose=2, validation_split=0.2)
plotLosses(history)

Evaluating the CNN (with dropout and batch normalization)¶
score = model.evaluate(X_test, y_test, batch_size=128, verbose=0)
print(model.metrics_names)
print(score)
3.3 Data Augmentation¶
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=True) # flip images horizontally
validation_datagen = ImageDataGenerator()
train_generator = train_datagen.flow(X_train[:40000], y_train[:40000], batch_size=32)
validation_generator = validation_datagen.flow(X_train[40000:], y_train[40000:], batch_size=32)
from keras.optimizers import Adam
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3)))
# Batch normalization layer added here
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256))
# Batch normalization layer added here
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
adam = Adam(lr=0.0006, beta_1=0.9, beta_2=0.999, decay=0.0)
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer=adam)
# fits the model on batches with real-time data augmentation:
history = model.fit_generator(train_generator,
validation_data=validation_generator,
validation_steps=len(X_train[40000:]) / 32,
steps_per_epoch=len(X_train[:40000]) / 32,
epochs=15,
verbose=2)
plotLosses(history)

Evaluating the CNN (with dropout, batch normalization and data augmentation)¶
score = model.evaluate(X_test, y_test, batch_size=128, verbose=0)
print(model.metrics_names)
print(score)
Training example with small dataset (1000 images)¶
To demonstrate the usefulness of data augmentation, let's see what happens if we only train with 1000 images instead of 50000.
The learning process without image augmentation:
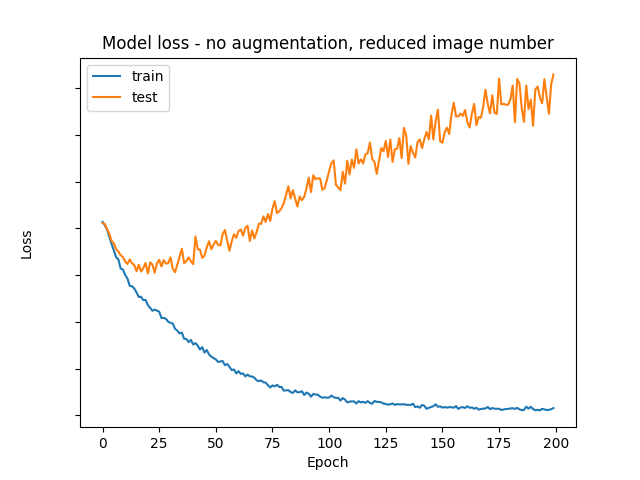
The learning process with image augmentation:
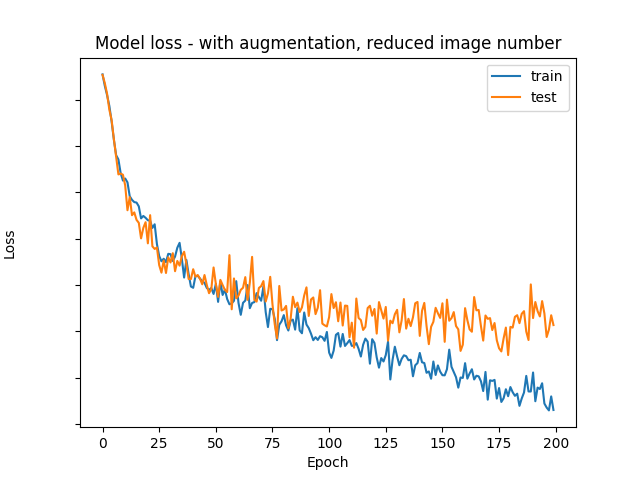
The following part of the tutorial is based on Magnus Erik Hvass Pedersen's work which can be found on Github.
4. Transfer learning¶
It is common practice to use pretrained networks in image processing, since large datasets are relatively uncommon, the training of a large network requires significant resources and it usually takes a long time (e.g. modern networks take 2-3 weeks to train across multiple GPUs on ImageNet, which contains 1.2 million images with 1000 categories).
Inception V3¶
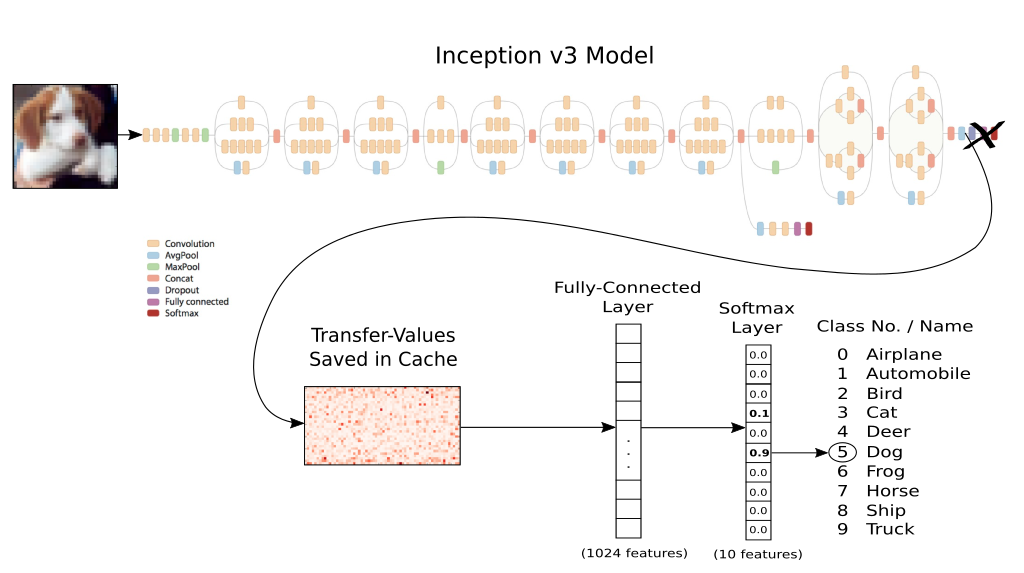
The Inception model is a pretrained network for the ImageNet challenge, released by Google. The namesake of the network are the Inception modules, which are basically smaller models inside the bigger model. The same architecture was used in the GoogLeNet model, which was a state of the art image recognition model in 2014.
First, lets preview our classification process of CIFAR-10! Since the Inception model is enormous compared to the networks we have worked with so far, it would take too much time to train the whole network. The trick is to add new classification layers to it, and train only those. While we do not have to actually train the Inception model, we do need to generate output for the CIFAR-10 dataset, which is quite tedious by itself. The output of a single image is going to be a 2048 dimension vector, illustrated below as 'Transfer-Values Saved in Cache'. After we generate this output vector for all the images, we can feed them to a simple classification network.
Loading the dataset¶
While the CIFAR-10 dataset is easily accessible in keras, these 32x32 pixel images cannot be fed as the input of the Inceptionv3 model as they are too small. For the sake of simplicity we will use an other library to load and upscale the images, then calculate the output of the Inceptionv3 model for the CIFAR-10 images as seen above.
from download_data.data_downloader import maybe_download_and_extract
url = "https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz"
download_dir = "data/"
maybe_download_and_extract(url, download_dir)
We need to reshape the images to have the 32x32x3 data structure.
from load_data.data_loader import load_data
import numpy as np
dataset = load_data(download_dir)
dataset['images_train'] = np.reshape(dataset['images_train'], (-1, 3, 32, 32))
dataset['images_train'] = np.transpose(dataset['images_train'], (0,2,3,1))
dataset['images_test'] = np.reshape(dataset['images_test'], (-1, 3, 32, 32))
dataset['images_test'] = np.transpose(dataset['images_test'], (0,2,3,1))
from keras.utils.np_utils import to_categorical
categorical_labels = to_categorical(dataset['labels_train'], num_classes=10)
categorical_test_labels = to_categorical(dataset['labels_test'], num_classes=10)
Loading the model¶
from inception import inception
inception.maybe_download()
model = inception.Inception()
Classification with the Inception V3¶
Before we do anything with the model, let's try to classify an image with it.
This image is of a tram (or speedcar) and it has the desired input shape of the Inception model: (299, 299, 3).
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import matplotlib.image as mpimg
img = mpimg.imread("images/tram.jpg")
plt.imshow(img)
plt.show()
img.shape

After generating the prediction, we use the print_scores function to display the top k (5 in this case) predictions of the model.
prediction = model.classify(image = img)
model.print_scores(pred = prediction, k=5)
Generating Inception V3 outputs¶
As mentioned before, we need to generate the output of the Inception model for every CIFAR-10 image as 2048-dimension vectors.
import os
# Setting up file paths to save the generated output
output_path = "inception/"
inception_train_output_path = os.path.join(output_path, 'inception_cifar10_train.pkl')
inception_test_output_path = os.path.join(output_path, 'inception_cifar10_test.pkl')
from inception.inception import transfer_values_cache
# The transfer_values_cache function is used to generate the Inception outputs from the dataset images.
print("Generating Inception output for train images...")
inception_train_output = transfer_values_cache(cache_path=inception_train_output_path,
images=dataset['images_train'],
model=model)
print("Generating Inception output for test images...")
inception_test_output = transfer_values_cache(cache_path=inception_test_output_path,
images=dataset['images_test'],
model=model)
model.close()
print("Inception input image: ")
plt.imshow(dataset['images_train'][20]/255)
plt.show()
print("Inception output: ")
plt.imshow(inception_train_output[20].reshape((32,64)), cmap='Greens')
plt.show()


Creating the classifier¶
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout
model = Sequential()
model.add(Dense(1024, activation='relu', input_dim=inception_train_output.shape[1]))
model.add(Dropout(0.25))
model.add(Dense(512, activation='relu'))
model.add(Dense(10, activation='softmax'))
adam = Adam(lr=0.0006, beta_1=0.9, beta_2=0.999, decay=0.0)
model.compile(optimizer=adam,
loss='categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(inception_train_output,categorical_labels, epochs=10, batch_size=32, verbose=2, validation_split=0.2)
plotLosses(history)

score = model.evaluate(inception_test_output, categorical_test_labels, batch_size=128, verbose=0)
print(model.metrics_names)
print(score)
5. Ensemble¶
The ensemble method is a technique to create several models combine them to produce improved prediction results.
There are several ways to combine these models. We could determine the combined prediction by calculating a mean of the prediction, or we could use a vote system: the label which get more vote wins.
In this example, we will simply calculate the average of the predictions.
Saving predictions for the test dataset¶
The following function saves the predictions of the test set as a file.
import os
def savePredictions(model):
predictions = model.predict(inception_test_output, batch_size=32, verbose=0)
save_dir = 'predictions/'
i = 0
while os.path.exists(os.path.join(save_dir, "predictions_%s.npy" % i)):
i += 1
np.save(os.path.join(save_dir, "predictions_%s.npy" % i), predictions)
When we have collected all predictions, we need a function to calculate the mean of these predictions, and evaluate its accuracy.
def calculate_ensemble_accuracy(all_predictions):
all_predictions = np.array(all_predictions)
ensemble_predictions = np.mean(all_predictions, axis = 0)
ensemble_class_predictions = np.argmax(ensemble_predictions, axis=1)
ensemble_accuracy = np.sum((ensemble_class_predictions == dataset['labels_test'])) / len(dataset['labels_test'])
return ensemble_accuracy
With this function, we can monitor the change of the ensemble's accuracy as we add more models to it.
import glob
import matplotlib.pyplot as plt
def evaluate_ensemble():
load_dir = 'predictions/'
all_predictions = []
current_accuracy = []
ensemble_num = 0
for filename in sorted(glob.glob(os.path.join(load_dir, '*.npy'))):
predictions = np.load(filename)
all_predictions.append(predictions)
ensemble_num += 1
current_accuracy.append(calculate_ensemble_accuracy(all_predictions))
ensemble_accuracy = calculate_ensemble_accuracy(all_predictions)
print('Ensemble accuracy: ' , ensemble_accuracy)
print('Number of networks in the ensemble: ', ensemble_num)
plt.figure(figsize=(7,8))
plt.plot(range(1,len(current_accuracy)+1),current_accuracy, linewidth=0.5, marker='o')
plt.grid(linestyle='dotted')
plt.xlabel('Network count', fontsize='large')
plt.ylabel('Accuracy', fontsize='large')
plt.show()
savePredictions(model)
evaluate_ensemble()
