|
John Davies, Richard Weeks, Mike Revett
BT Laboratories
Ipswich
IP5 7RE
UK
January 1996
- Abstract
-
- This paper discusses a distributed system of intelligent agents for performing information tasks over the Internet
WorldWideWeb (W3) on behalf of a user or community of users. We describe how agents are used to store, retrieve,
summarise and inform other agents about information found on W3. Most current W3 clients (Mosaic, Netscape, and so
on) provide some means of storing pages of interest to the user. Typically, this is done by allowing the user to create a
(possibly hierarchical) menu of names associated with particular URLs. While useful, this quickly becomes unwieldy
when a reasonably large number of W3 pages are involved.
The solution we adopt to this problem is to allow the user to access information by a much richer set of meta-information
than simply names assigned to particular URLs. Given the vast amount of information available on W3, it is preferable to
avoid the copying of information from its original location to a local server. The local storage of only relevant
meta-information also addresses this issue. The meta-information used includes automatically extracted keywords and
summary, as well as the document title, universal resource locator (URL) and date and time of access. This
meta-information is then used to index on the actual information when a retrieval request is made.
When an agent stores a page, it will also automatically inform other users who it considers will be interested of the page's
discovery via an email message. Thus Jasper is a small step towards automating the original vision for W3 as a network
which supports co-operative working and the sharing of information. In addition, Jasper agents will modify a user's profile
as the type of information the user is accessing changes. Pages stored in Jasper can be posted to interest groups, creating
shared information resources about specific topics.
-
- Keywords:
- Information agent, information sharing, information filtering, user profiling, information management, text summarisation
In 1982, the volume of scientific, corporate and technical information was doubling every 5 years. By 1988, it was doubling
every 2.2 years and by 1992 every 1.6 years. With the expansion of the Internet and other networks the rate of increase will
continue to increase. Key to the viability of such networks, will be the ability to manage the information and provide users with
the information they want, when they want it.
This paper discusses a distributed system of intelligent agents for performing information tasks over the Internet
WorldWideWeb (W3) on behalf of a user or community of users. Below we describe how agents are used to store, retrieve,
summarise and inform other agents about information found on W3 in a system called Jasper (Joint Access to Stored Pages
with Easy Retrieval). In certain circumstances, Jasper agents will also identify an opportunity for performance improvement and
will seek user feedback in order to improve.
Our approach is not motivated by any perceived requirement for another tool for searching W3: there are already many of these
[1,2] and they are being added to frequently with ever increasing coverage of the web and sophistication of search engines. Our
motivation is different but related: having found useful information on W3, how can it be stored for easy retrieval and how can
other users likely to be interested in the information be identified and informed?
Given the vast amount of information available on W3, it is preferable to avoid the copying of information from its original
location to a local server. Indeed, it could be argued that approach is contrary to the whole ethos of the web. Rather than
copying information, therefore, Jasper agents store only relevant meta-information. As we will see below, this includes
keywords, a summary, document title, universal resource locator (URL) and date and time of access. This meta-information is
then used to index on the actual information when a retrieval request is made.
Jasper agents also have the capability to learn their user's interests by observing the user's behaviour. As the user stores more
pages, the user profile held by the Jasper agent is modified automatically to better reflect the topics of interest to the user, as
evidenced by the pages they have stored.
Most current W3 clients (Mosaic, Netscape, and so on) provide some means of storing pages of interest to the user. Typically,
this is done by allowing the user to create a hierarchical menu of names associated with particular URLs. While this menu facility
is useful, it quickly becomes unwieldy when a reasonably large number of W3 pages are involved. Essentially, the representation
provided is not rich enough to allow us to capture all we would like about the information stored: the user can only provide a
string naming the page. As well as the fact that useful meta-information such as the date of access of the page is lost, a single
phrase (the name) may not be enough to accurately index a page in all contexts. Consider, as a simple example, information
about the use of knowledge-based systems (KBS) in information retrieval of pharmacological data: in different contexts, it may
be KBS, information retrieval or pharmacology which are of interest. Unless a name is carefully chosen to mention all three
aspects, the information will be missed in one or more of its useful contexts. This problem is analogous to the problem of finding
files containing desired information in a Unix (or other) file system [3], although in most filing systems one at least has the facility
to sort files by creation date.
The solution we adopt to this problem is to allow the user to access information by a much richer set of meta-information. How
Jasper agents achieve this and how the resulting meta-information is exploited is the subject of the next section.
In this section, we will discuss the facilities which Jasper agents offer the user in managing information. These can be grouped in
two categories, storage and retrieval.
Figure 1 shows the actions taken when Jasper stores information in its intelligent page store (IPS). The user first finds a W3
page of sufficient interest to be stored by Jasper in his IPS and sends a 'store' request to Jasper via a menu option on his
favourite W3 client (Mosaic and Netscape versions are currently available on all platforms). Jasper then invites the user to
supply an annotation to be stored with the form. Typically, this might be the reason the page was stored and can be very useful
for other users in deciding which pages retrieved from IPS to visit. The user can also specify at this point one of a predefined set
of interest groups to which to post the page being stored. We discuss information sharing and interest groups further below.
Jasper next extracts the source text from the page in question, first stripping out HTML tags. Jasper then sends the text to BT's
text summarisation system, NetSumm. The size of the summary thus obtained can be controlled by the parameters passed to
NetSumm. Jasper then derives a set of keywords from the source text.
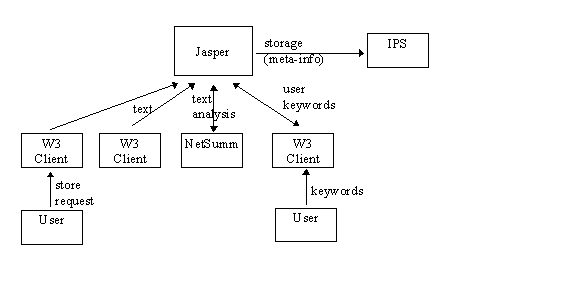
Figure 1. Jasper's Storage Process
At the end of this process, Jasper has the following meta-information about the W3 page of interest:
- a set of keywords;
- the user's annotations;
- a summary of the page's content;
- the document title;
- universal resource locator (URL) and
- date and time of storage.
Jasper then adds the page to the IPS. In the IPS, the keywords (of both types) are then used to index on files containing the
other meta-information, as shown in Figure 2 below.
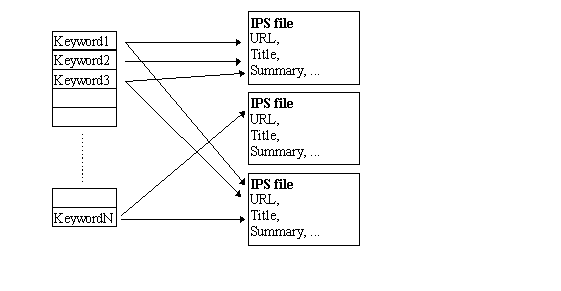
Figure 2. IPS Structure
There are four modes in which information can be retrieved from IPS using Jasper. One is a standard keyword retrieval facility,
while the other three are concerned with information sharing between a community of agents and their users. We will describe
each in turn in the sections below.
When a Jasper agent is installed on a user's machine, the user provides a personal profile: a set of keywords which describe
information he is interested in obtaining via W3. This profile is held by the agent in order to determine which pages are
potentially of interest to its user. The way this is done is described below.
Keyword retrieval
As is shown in Figure 3, for straightforward keyword retrieval, the user supplies a set of keywords to his Jasper agent via an
HTML form provided by Jasper. The Jasper agent then retrieves the ten most closely matching pages held in IPS, using a
simple keyword matching and scoring algorithm. The user can specify in advance a retrieval threshold below which pages will
not be displayed. The agent then dynamically constructs an HTML page with a ranked list of links to the pages retrieved and
their summaries. Any annotation made by the original user is also shown, along with the scores of each retrieved page. This
page is then presented to the user on his or her W3 client.
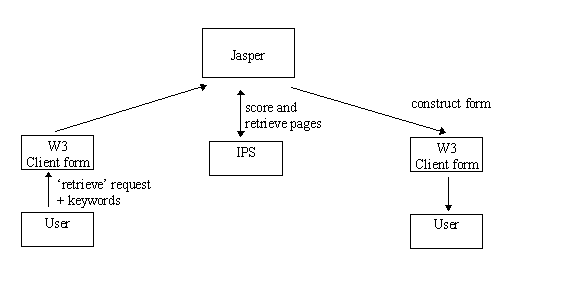
Figure 3. Jasper's Keyword Retrieval Process
"What's New?" facility
Any user can ask his Jasper agent "What's new?" The agent then interrogates the IPS and retrieves the most recently stored
pages. It then determines which of these pages best match the user's profile based on the same keyword matching algorithm as
that mentioned above. An HTML page is then presented to the user showing a ranked list of links to the recently stored pages
which best match the user's profile and the other pages most recently stored in IPS, with annotations where provided. Thus the
user is provided with a view both of the pages recently stored of most interest to himself and of a more general selection of
recently stored pages.
A user can update the profile which his Jasper agent holds at any time via an HTML form which allows him to add and/or delete
keywords from the profile. In this way, the user can effectively select different contexts in which he wishes to work. A context
is defined by a set of keywords (those making up the profile or, indeed, those specified in a retrieval query) and can be thought
of as those types of information which a user is interested in at a given time.
The idea of applying human memory models to the filing of information was explored by Jones [3] in the context of computer
filing systems. Building on his ideas, we can draw an analogy between a directory in a file system and a set of pages retrieved by
a Jasper agent. The set of pages can be thought of as a dynamically-constructed directory, defined by the context in which it
was retrieved. This is a highly flexible notion of 'directory' in two senses: first, pages which occur in this retrieval can of course
occur in others, depending on the context and second, there is no sharp boundary to the directory: pages are 'in' the directory to
a greater or lesser extent depending on their match to the current context. In our approach, the number of ways of partitioning
the information on the pages is thus only limited by the diversity and richness of the information itself.
Communication with other interested agents
Jasper agents are currently being trialled by a group of users on a W3 server at BT Laboratories. When a page is stored in IPS
by a Jasper agent, the agent checks the profiles of other agents' users in its 'local community' (here the agents in the trial,
although this could be any predefined community). If the page matches a user's profile with a score above a certain threshold, an
email message is automatically generated by the agent and sent to the user concerned, informing him of the discovery of the
page.
The email header is in the format:
JASPER KW: {keyword}*
This allows the user before reading the body of the message to identify it as being one from Jasper and since a list of keywords
is provided the user can assess the relative importance of the information to which the message refers. The keywords in the
message header vary from user to user depending on the keywords from the page which match the keywords in their user
profile, thus personalising the message to each user's interests. The message body itself informs the user of the page title and
URL, who stored the page and any annotation to the page which the storer provided.
Other forms of automatic notification (e.g. via dynamically constructed W3 pages) are also being studied.
As we argue in below, the ability to share relevant W3 information with other users quickly and easily is a key part of the
original vision of W3. A Jasper agent can automate this information task for a user to some extent.
Jasper Interest Groups
As mentioned above, when a user stores a page in Jasper, he has an opportunity to specify one of a predefined set of interest
groups to which to post the page. Interest groups are somewhat analogous to Usenet newsgroups and gather together pages of
related information. Examples of interest groups which have been used are: Artificial Intelligence, ATM, Agents, Data Mining,
Films, and Electronic Commerce.
Jasper users can visit interest group pages which are dynamically constructed from the pages which have been posted to them
and consist of a list of links to the pages and their summaries, along with any annotation provided by the original storer of the
page.
Interest groups are similar to the 'list of links' pages found in many W3 locations, with the important extensions that multiple
users can contribute to the list (automatically via the storage process) and that summaries of the information and annotations by
the original poster of the link are available.
Interest groups can be thought of an alternative to Jasper's automatic emailing facility as a way of sharing information among
Jasper users. It complements the email facility in that it is less immediate, email messages being generated by Jasper agents as
soon as a page is stored, but more permanent. It is also a way of clustering the stored pages into related topic areas.
Learning from Feedback
In certain circumstances, Jasper agents will identify an opportunity for performance improvement and will seek user feedback in
order to maximise the performance enhancement.
A Jasper agent can modify a user's profile if the agent identifies that the profile does not reflect the pages which the user is
storing. When a page is stored, the agent compares the content of the page
with the user's profile. If the profile does not match the page content above a given threshold, Jasper informs the user and invites
the user to modify his profile by adding some keywords suggested by the agent based on the page's content.
The user can then select from the suggested keywords and/or provide some new keywords of his own to be added to the
profile. In this way, the user profile should evolve over time to better reflect the user's interests or indeed evolve as those
interests change.
Related Work
The services provided by existing Internet information retrieval tools can be divided into four main functions: search, storage,
access and organisation.
There are many systems which offer some or all of these to the W3 user, including WAIS [10], Archie [11] and the Harvest
system [9]. Harvest is one of the most sophisticated of these types of system and we briefly describe Harvest and compare it
with Jasper. All the systems mentioned above can be characterised as 'off-line' systems in the sense that their indexes and stores
are not built incrementally as in Jasper but are rather constructed off-line for later use. The key elements of the Harvest
approach are gatherers and brokers. Gatherers collects indexing information from a given collection of information (http, ftp
and gopher protocols are supported). Brokers provide query interfaces to the gathered information. Brokers can access more
than one gatherer, as well as other brokers. Experiments indicate that Harvest reduces load on servers and networks. This is
due to efficient gathering software and the sharing of information among indexes that need it, in contrast to other comparable
information retrievers which use expensive object retrieval protocols and fail to co-ordinate information gathering among
themselves.
Harvest queries on W3 brokers return references to relevant information sources, an indication of the degree of match to the
query and a content summary. The summarisation performed on text files is simply to extract the first 100 lines plus the first
sentence of each remaining paragraph. Keywords seem to be an alphabetical list of this summary. It is possible in principle to
write and plug in your own summariser. Harvest also 'summarises' other formats of information, albeit in a fairly simple way. The
summary of an audio file, for example, is the file name, while the summary of a perl script is the procedure names and comments
therein.
Harvest and Jasper thus differ in several ways: firstly, Harvest is inherently 'off-line' as discussed above while Jasper is
'incremental'. Secondly, Harvest summaries are more simplistic than those attempted by Jasper, although Harvest provides
'summaries' of a wider range of information types.
More similar to Jasper than off-line indexers of information is 'Warmlist' [12], a tool for caching, searching and sharing W3
documents. Like Jasper, Warmlist extends the idea of the hotlist. W3 documents in the Warmlist are automatically cached on
the local server, along with the original links to other information. This gives much quicker access to Warmlist pages. A useful
feature of a Warmlist is the ability to include other Warmlists as part of one's own Warmlist. The Glimpse indexing and
searching package [13] is used to search cached pages.
In Jasper, we take a different approach by not storing whole pages but rather storing meta-information about a page. As
described above, this allows much enhanced, richer indexing on pages of interest without the necessity of copying remote
information to local servers. It is possible that with many users on a W3 server using Warmlist, the server would rapidly fill up
with cached pages. Also the concept of a page being copied and stored in many different places (i.e. on multiple Warmlists)
seems somewhat against the ethos of the web. Given that Warmlist caches entire pages, it is unsurprising that it provides no
facilities for information summarisation.
W3 documents in a Warmlist can be organised in a hierarchical way with nested directories. As we have argued above,
however, a more flexible way to access information is via a set of keywords describing the contents of the page. This removes
the necessity to remember where documents have been stored (e.g. Did I store the letter to Smith about the Internet in
letters/smith/Internet or Internet/letters or smith/letters or ...?)
We mentioned above the four main functions (search, storage, access and organisation) common to many Internet information
tools. In the Jasper system, we have taken the first steps towards adding two further functions: firstly, automated information
sharing; secondly, the ability of the agent to model the user's interests based on the user's interaction with the tool. This
functionality is not provided by any other Internet tools of which we are aware.
In this section, we describe several areas of ongoing or future work.
Jasper agents currently use a very simple keyword retrieval algorithm. No doubt the precision of retrievals could be improved
by the adoption of more advanced retrieval techniques such as vector space or probabilistic models [5]. However, the main
thrust of the work reported here is not the implementation of document retrieval algorithms but rather an investigation into novel
ways of organising W3 information. An improved retrieval algorithm will nevertheless be included in a future version of Jasper.
Another area of work is the improvement of retrieval capabilities in other directions. Currently, Jasper agents only index pages
by keywords. In the introduction to this paper, we discussed the limitations of the filename-oriented approach of standard
operating systems. We elaborate on this below and suggest a solution to the problem currently being implemented in Jasper.
There are two main problems with the use of filenames to retrieve information: recall (remembering the name of a file containing
particular information) and recognition (knowing the information contained in a given file). As discussed above, we have
addressed this problem in Jasper by indexing the information stored on multiple terms (keywords). We now intend to extend
this approach in two ways.
Firstly, we will allow indexing on meta-information other than keywords. Initially, the extra meta-information will be the date of
storage of a page and the originating site of the page (which Jasper can extract from the URL). These extra indices will allow
users (via an HTML form) to frame commands of the type:
Show me all pages I stored in 1994 from Cambridge University about artificial intelligence and information retrieval.
An initial version of this capability has been added to the system, allowing the user to specify the date range of the pages to be
retrieved.
Secondly, a thesaurus will be used by Jasper to exploit keyword synonyms. This will reduce the importance of entering
precisely the same keywords as were used when a page was stored. Indeed, it is intended to exploit the thesaurus in several
other areas, including the personal profiles which an agent holds for its user. Detailed discussion of this idea is beyond the scope
of the present paper. In addition, it is hoped that this profile enhancement process will help to improve the relevance of email
messages sent by Jasper agents to users. In the current trial, it has been found that overgeneration of email messages can be a
problem. This can lead to users preferring to use the What's New? and Interest Group retrieval mechanisms. In effect, there is
currently a trade-off between accuracy on the one hand and timeliness and automation on the other: email messages are
immediate and proactive but may sometimes be irrelevant, while the other retrieval mechanisms require more effort on the part
of the user and are slower but typically yield a higher percentage of relevant information. Feedback from users indicates that the
potential of the email approach is recognised and with improved accuracy would be the preferred mechanism.
The use of user profiles by Jasper agents to determine information relevant to their users, though powerful, is currently
somewhat clumsy. When the user wants to change context (perhaps refocusing from one task to another, or from work to
leisure), he must re-specify his profile by adding and/or deleting keywords. A better approach would be for the agent to change
the user's profile as the interests of the user change over time. This change of context to occur in two ways: there could be a
short-term switch of context from, for example, work to leisure. The agent should identify this from a list of current contexts it
holds for a user and change into the new context. This change could be triggered, for example, when a new page of different
information type is visited by the user. There will also be longer term changes in the contexts the agent holds based on evolving
interests of the user. These changes can be inferred from observation of the user by the agent. Work has not yet begun in this
area but techniques under investigation for a learning agent include genetic algorithms, learning from feedback and
memory-based reasoning [3,7].
Finally, a possible further development of Jasper would be to integrate the user's own computer filing system with the IPS, so
that information found on W3 and on the local machine would appear homogenous to the user at the top level. Files could then
be accessed similarly to the way in which Jasper agents access W3 pages, freeing the user from the constraints of
name-oriented filing systems and providing a contents-addressable interface to both local and remote information of all kinds.
In his seminal article, Bush [6] describes a tool to aid the human mind in dealing with information. He states that previous
scientific advances have helped humans in their interactions with the physical world but have not assisted humans in dealing with
large amounts of knowledge and information. Bush proposed a tool called a 'memex' which could augment human memory
through associative memory, where related pieces of information are linked. Trails through these links could then be stored and
shared by others. W3 itself fulfils Bush's vision in some respects: Bush's associative memory can be seen in the hyperlinks of
W3. What is lacking is a way of organising this vast 'memory' of W3 pages into coherent 'trails' which can be saved and
communicated to others. Currently, only relatively simplistic hotlists and menus are available.
Jasper goes some way to addressing these problems by providing agents which, as we have seen, can store meta-information
about W3 pages which can then be used to retrieve relevant pages quickly and easily and share the information contained in
those pages with other users with the same interests. Jasper leaves aside the issue of how best to search W3 for information
(many other researchers are working on this) and is an attempt to address the complementary problem of how best to store
information once it has been found and how to share information with others with the same interests. As we have discussed,
Jasper agents also have the ability to proactively suggest improvements to users' profiles based on the behaviour of the user.
As discussed above, much remains to be done: in particular, the exploitation of more of the meta-information obtained by
Jasper agents, improving the ability of a Jasper agent to identify pages of interest to a user and the provision of adaptive agents
which can infer context from users' actions will be useful enhancements to the current system. However, we believe Jasper is a
small step along the road towards the original vision for W3 [8] as a network which supports co-operative working and the
sharing of information.
Mike Knul of BT Laboratories contributed to the early discussions which led to the development of Jasper.
[1] http://lycos.cs.cmu.edu .
[2] http://www.stir.ac.uk/jsbin/jsii
[3] Jones, W.P., "On the applied use of human memory models: the memory extender personal filing system", Int. J.
Man-Machine Studies, 25, 191-228, 1986.
[4] Lahkari, Y., Metral, M. & Maes, P., "Collaborative Interface Agents", MIT Internal Report , 1994.
[5] Salton, G., "Automatic Text Processing", Addision-Wesley, Reading, Mass., USA, 1989.
[6] Bush, V., "As We May Think", The Atlantic Monthly, July 1945. Also available as
http://www.csi.uottawa.ca/~dduchier/misc/vbush/as-we-may-think.html .
[7] Sheth, B. & Maes, P., " NEWT: A Learning Appraoch to Personalised Information Filtering", MIT Thesis, 1993.
[8] Berners-Lee, T., http://www10.w3.org/hypertext/W3/Summary.html .
[9] Bowman, C.M., Danzig, P.B., Hardy, D., Manber, U. & Schwartz, M., "The Harvest Information Discovery and Access
System", Proc. 2nd Intl WWW Conf., Chicago Illinois, US, October 1994.
[10] Brewster, K. & Medlar, a., "An Information System for Corporate Users: Wide Area Information Servers", Connections -
The Interoperability Report, 5(11), November 1991. Also available from ftp://think.com/wais/wais-corporate-paper.text .
[11] Emtage, A. & Deutsch, P., "Archie: an electronic directory service for the Internet", Proc. Usenix Winter Conference,
January 1992.
[12] Klark, P. & Manber, U., "Developing a Personal Internet Assistant",
http://glimpse.cs.arizona.edu:1994/~paul/warmlist/paper.html .
[13] Manber, U. & Wu, S., "GLIMPSE: A Tool to Search through Entire File Systems, Usenix Winter 1994 Technical
Conference, San Fransisco, US, January 1994.
About the Authors
John Davies, Richard Weeks & Mike Revett
Advanced Applications & Technology
BT Laboratories
Ipswich
IP5 7RE
UK
email: {john.davies ,richard.weeks,mike.revett}@bt-sys.bt.co.uk
| 