István Majzik
Department of Measurement and Instrument Engineering
Technical University of Budapest
H-1521 Budapest Muegyetem rkp. 9. R.103., Hungary
Phone: +36-1-463 2057
E-mail: majzik@mmt.bme.hu
1995-1996
The trustworthiness of a computer system is characterized by its dependability. A system is dependable if ''reliance can justifiably be placed the service it delivers'' [Lap92]. Different attributes of the dependability are availability (readiness for usage), reliability (continuity of service), safety (avoidance of catastrophic consequences on the environment) and security (prevention of unauthorized access). The reliability of a system is a time dependent function, the probability that the lifetime of the system exceeds a predefined time (assumed that at zero system time its was operational). Availability is the probability that the system is operational at the given point in time.
A system failure occurs when the service of the system does not comply with the specification, the behavior of the system deviates from that required by the user. The cause of a system failure is an erroneous transition of the system state, caused either the failure of a system component or an erroneous design. An error is that part of the system state (a defective value) which is liable to lead to failure. Whether or not an error leads to a failure depends on the system composition (applied redundancy) or on the activity of the system (an error may be overwritten). The adjudged or hypothesized cause of an error is a fault.
Faults and their sources are diverse, a classification is possible on the nature, origin and persistence:
Temporary external faults originating from the physical environment are referred to as transient faults, while temporary internal faults are referred to as intermittent faults (e.g. marginal timing, load or pattern sensitive situations which occur rarely).
The manifestation mechanism of faults, errors and failures is summarized by the chain
![]()
A subcomponent fault leads to a component failure, which can be interpreted as fault of the component which results in system failure etc. Failure modes of a system component can be viewed as fault types for the system. A fault is active when it produces an error, dormant otherwise. An active fault is an external fault or a previously dormant one which was activated by the computation of the system. An error is latent prior to its detection, detected if it is recognized by some detection mechanism.
The development of a dependable computing system includes a set of methods. In the design and implementation phase, fault avoidance by proved design methodologies, technologies and formal verification is important. In the test and debugging phase, fault removal is performed. Both methods can be referred to as fault prevention, preventing fault occurrence or introduction. In the operational phase, fault tolerance methods are applied to provide a proper system service in spite of faults. Fault forecasting is used to estimate the number, future incidence and consequences of faults. The notions of dependability are summarized in Table 1.1.

Table 1.1: Notions of dependability
Fault tolerance, i.e. how to prevent faults and errors leading to a failure, includes four phases as follows [LA90]:
The task of the error detection mechanisms is to find out whether the actual state of the system is erroneous. The original system is supplemented by additional components which perform the check. Ideal checks (i) are based solely on the specification, (ii) check the complete behavior of the system and (iii) are independent of the checked system (to avoid the effects of errors to the checks) [LA90]. The incomplete specification, the complexity of the system and the need of accessing the information to be checked usually prevents the implementation of an ideal checker. Acceptability checks, which are less strict, mean that the absence of errors is not guaranteed, but the results can still be accepted with a high probability.
The main characteristics of error detection are the overhead required to implement the check, the error latency and coverage. Low latency is especially important to avoid the spread of error effects and damage of critical system components (e.g. recovery data). A long error latency can also prevent the fault diagnosis by the weak correlation between the fault and its symptoms.
Error detection, as well as fault tolerant operation of the system, is based on some form of redundancy, i.e. utilization of extra elements. System redundancy may include
Error detection can be performed off-line, when the system is inactive (or is in idle state) or on-line, when the system is operational. The latter is referred to as concurrent error detection. Note that detection of transient faults requires continuous, concurrent error detection. Off-line checks usually include the systematic testing of the system by supplying special inputs (test patterns) to the components and investigating the outputs. The purpose is either to check whether the component satisfies the specification (conformance testing) or to reveal some (hypothesized) faults (fault testing). This type of checks have high coverage but are expensive in resources and time, this way they are rarely implemented as concurrent checks (diagnostic checks).
The checks used for concurrent error detection highly utilize the redundancies built in into the system. They are categorized in [LA90] as follows:
To develop and use an error detection method a fault model has to be first established and analyzed. It describes the possible faults and their effects (errors) at the appropriate level of the system model. Structural fault models deal with the faults of the various system components, functional fault models describe the possible malfunctions of the system.
The investigation of the types and effects of faults in microprocessor systems is a topic of continuous research. As the complexity and speed of the devices increases, more and new fault and error types should be taken into account. In most cases, the complexity of the device or the incomplete knowledge of the internal structure and operation prevents the elaboration of a detailed, low level (gate or register transfer level) fault model, this way a meaningful analytical estimation of the effects of low-level faults to the behavior of the system is difficult to achieve. This is particularly true for transient faults, since this class does not have a good characterization. If the internal structure of the device under investigation is available then simulation based techniques can be applied (especially in the design phase), otherwise the experimental evaluation by hardware-based fault injection is a widely used technique (in the prototype phase). The collection of the error log of systems is another source of the analysis (in operational phase).
In the following, some results of the research presented in the literature are surveyed. Since the goal is to find efficient and high coverage on-line error detection techniques for microprocessor based systems, the overview is focussed on microprocessors and related errors which are (relatively) easy to detect. The applied techniques include simulation [ORG92], fault injection by heavy-ion radiation [KGT89], power disturbances or modification of signals of the system bus [STDM82], [MQS90]. (Software based injection techniques, since they model the effects of faults directly at the error level, are obviously excluded from our survey.)
The first important result of the studies is that transient and intermittent faults are the major causes for digital system failures. It is estimated that they occur 10 to 30 times more frequently than permanent faults, which means that they cause more than 90% of the failures in computers [SS82], [SL81]. Transient faults are caused mainly by power jitter, electro-magnetic interference, ionization by cosmic rays or alpha particles (from packaging materials). A minor extent (intermittent faults) is caused by design faults (e.g. fan-in, marginal circuits, oscillation between active and inactive states etc.). The decreasing sizes of chips and the high speeds achieved today make them more sensitive (the difference between the logic levels tends to be lower and the time margins are reduced). In industrial environments where power disturbances and electro-magnetic interference are frequent, transient faults play an even more important role.
In [KGT89] the following rough characterization of transient faults is introduced:
The effects of transient faults induced by heavy ion radiation were investigated by physical fault injection. The external signals of the test processor (MC 6809E) were compared to a reference processor running the same program (without radiation), that is, a master-checker configuration was established. 70% of the detected errors were single bit errors. The above categories are presented in Table 1.2 for two benchmarks.
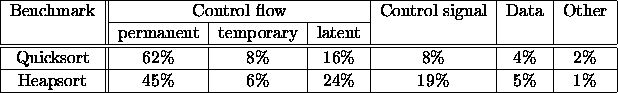
Table 1.2: Classification of effective errors
In [STDM82] a more detailed classification was performed. The control flow, memory access behavior and address values were examined and the following categories were established:
The transient faults was generated explicitly, modifying the signals of the system bus (stuck-at-0 and stuck-at-1 faults, varying the time of the activation). The effects (processor state, external signals) of a test program run were compared to a fault-free run. The results of each individual error category are summarized in Table 1.3.
Similar (but less) categories were established in [MQS90]. Transient faults were inserted similarly by modifying the bus signals of a Z80 processor, the effects of the faults were detected by additional external circuits. The results are presented in the separated row of Table 1.3. Control flow was not monitored, and the different instruction set of the Z80 resulted in the low percentage of IOC.

Table 1.3: Classification of individual errors
The up-to-date RISC processors were investigated in [ORG92]. First the same categories were used as above in [KGT89], then the so-called basic error detection mechanisms which are often implemented in microprocessors (e.g. in the Motorola 68000 family) were also included:
Possible errors were evaluated through simulation-based fault injection. The register-level model of a TRIP microprocessor was written in VHDL, and transient faults were inserted by toggling a bit value of a randomly chosen internal state element. Only 23% of the faults resulted in effective errors, the others were overwritten or remained latent. The classification of the effective errors is presented in Table 1.4 (BAS means all basic errors, IO and PV are not separated). The main conclusion of the experiment is that only 33% of all effective errors resulted in control flow disturbance, compared to the 73% of the MC6809 non-pipelined CISC processor. The difference is likely the result of the architectural variations and the different fault injection methods. Clearly, the data error detecting methods are more important in RISC processors.
![]()
Table 1.4: Classification of effective errors in RISC processors
As a consequence of the above studies, the most efficient error detection mechanisms are, in addition to the data checking, the checking of control flow, memory access behavior and instruction codes. (The last one is efficient if not all bit patterns are used by the processor as instruction codes.) They are defined at a higher (behavioral) level, abstracted from the underlying gate- or register level models.
As the experiments have shown, a high portion of failures results from
transient faults. They are hard to be avoided by careful design (fault
avoidance) and testing during the manufacturing process (fault removal),
thus fault tolerance techniques are needed to improve the dependability
of the system. Since the dependability of the system is especially
sensitive to undetected or mishandled transient faults
[Sos94], the application of efficient error detection
techniques is of utmost interest. Moreover, in parallel computing
systems running long, computing intensive applications early error
detection is a vital requirement [CGH ![]() 93],
[CP94]. Regularly scheduled off-line tests are usually too
time consuming, without being able to detect transient faults, therefore
concurrent, on-line error detectors are preferred. Since transient
faults cause no permanent damage in the system, the chance of a
successful recovery is high, especially if the error coverage is high
and the latency is low (to avoid spreading the effects of the error and
damage of the recovery information).
93],
[CP94]. Regularly scheduled off-line tests are usually too
time consuming, without being able to detect transient faults, therefore
concurrent, on-line error detectors are preferred. Since transient
faults cause no permanent damage in the system, the chance of a
successful recovery is high, especially if the error coverage is high
and the latency is low (to avoid spreading the effects of the error and
damage of the recovery information).
From the point of view of the level of checking, concurrent error detectors can be divided into three categories: circuit, system and application level techniques. An other categorization is to distinguish checks provided by the ``interpreter'' (underlying hardware and operating system which maintains an interface on which the application is executed) and checks performed by the interpreted system (application). The general purpose checking facilities provided by the interpreter are referred to as mechanisms while the application-dependent ones explicitly programmed in the interpreted system are measures.
Circuit level detectors are mechanisms often built in into the system in the design phase when internal data paths and register-level building blocks are accessible, but are also used to detect errors on the external input or output pins of the chips. They are based on coding checks (redundancy of information). Primary inputs and outputs are encoded in an error detection code, and a checker is assigned to the module to highlight the errors (self-checking circuits, [Wak82]). Single words of data are checked e.g. by Hamming, Berger or n-out-of-m codes, data blocks (in transmission subsystems) are checked by cyclic codes. Checking of arithmetic or logic operations requires different type of codes, which are invariant to the operation. A*N codes, residue codes or parity prediction are widely used techniques. Such type of encoding and self-checking are applied to control sections (sequential circuits) too, but the main field of application is the error detection in data sections, where high coverage can be achieved using a small amount of redundancy.
Techniques used at the circuit level can be used within custom-design VLSI chips to provide the low-level detection of errors. However, due to increased circuit density and and a reduced access to the internal states of all modules (especially in the control section) the problem to detect errors in the overall behavior of the system is still open.
System level detectors aim at verifying the correctness by checking general properties of the system. They can be considered generally as guardians that check out invalid activities. The usual implementations perform replication checks by applying identical replicas or functionally equivalent variants and some adjudication (voter) unit. Hardware redundancy based techniques (including master-checker and other forms of structural replication, even with design diversity) compare the internal or external signals of the checked modules. The former requires tightly synchronized modules, the latter results in higher error latency. Time and software redundancy based replications repeat the computations of the system (several times) before producing the output signal. (Note that detection of permanent hardware faults requires different activation of the system resources.) Recovery block scheme, N-version programming and their modifications are widely used, differing mainly in how they organize the execution of the submodules (parallel, serial, adaptively etc.).
Hardware redundancy based error detection and fault masking are quite expensive, not admissible in low cost systems or in massively parallel systems. Software (and time) redundancy based techniques often lead to complex synchronization problems and represent high performance overhead [Daa86].
As low cost mechanism for (hardware-based) system level error detection, external monitoring devices are proposed. The hardware and time overhead is reduced as these monitors are relatively simple, since they examine only some selected properties of the system by peforming timing, interface and coding checks. Based on the fault injection experiments and practical observations, especially program timing (time-out of some operations), memory access (invalid read or write address, access to unused memory) and control flow (invalid control flow) are proposed as system properties to be monitored. These monitors are generally referred to as watchdog timers (WT) or watchdog processors (WP). Hardware (watchdog co-processor) as well as software (watchdog process) implementations are known. They are discussed in details in the following section.
Application level detectors are measures based on properties of
the particular algorithm executed by the system. Errors are detected
by assertions, invariant relationships among program variables. Usual
techniques include reversal, structural and reasonableness checks.
Another alternative is monitoring the behavior of the system at a high
level, from the point of view of the services to be delivered by the
application [TDM ![]() 94].
94].
Application level techniques are not automatical and transparent since the system programmer has to analyze the algorithm and derive the relationships and services to be checked. The assertions have to be inserted into the program in some form, the requirements to be checked has to be selected explicitly. These techniques are likely to have high error latency.
Comparing circuit, system and application level techniques we can conclude that the system level techniques become more and more important. First, as the complexity of the circuits grows, the cost/error coverage ratio of the circuit level techniques becomes less satisfactory. Second, using higher level checks, the less detailed elaboration of a fault model (the less knowledge about the detailed internal structure and operation of the system) is needed as more general properties of the system are checked. The error detection latency is an acceptable value between the low latency of the circuit level and high latency of the application level techniques. In the category of general purpose systems built upon commercial off-the-shelf (COTS) components, the efficient on-line error detection can be performed almost only by system level techniques.
A watchdog processor (WP) is a relatively small and simple coprocessor used to perform concurrent system-level error detection by monitoring the behavior of a main processor [Lu80], [MM88]. The general system architecture is shown in Figure 1.1. The watchdog is provided with some information about the state of the processor or process to be checked on the system (instruction and/or data) bus. Errors detected by the WP are signaled towards the checked processor or any external supervisory unit responsible for error treatment and recovery.
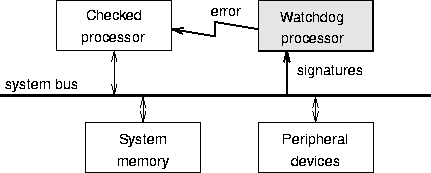
Figure 1.1: General system architecture with WP
From the point of view of information transfer, the operation of a watchdog processor is a two phase process. In the first, initialization phase the WP is provided with reference information about the fault-free operation of the checked processor. During the checker phase it is compared to the run-time information collected by the WP concurrently. In the case of a discrepancy, an error is detected. The scheme is the one of general testing: the WP compares the run-time information from the processor (device under test) with the reference one, the result of the comparison is a signal of Go/NoGo type.
The reference and run-time information checked by the WP can be about memory access behavior, control signals, control flow or reasonableness of results. To reduce the information transfer, the reference and run-time information is usually represented in a compacted form, by signatures (tokens).
Historically, the WP is an extension of the idea of watchdog timers (WT, [CPW72], [OCKB75]). Watchdog timers are simple hardware or software modules used to monitor concurrently the timing (duration) of selected system activities. Special reset sequences are embedded into the operation of the system which initialize the WT periodically. If it is not initialized within a specified time then a time-out is detected and an error signal is generated. Hardware implementations are popular in bus systems and communication circuits, software techniques are used e.g. in distributed operating systems or in real-time applications.
The application of watchdog processors as system level error detection technique has several advantages as follows:
The provide the above mentioned advantages, the design of watchdog processors is constrained by the following rules:
Mechanisms providing the best error coverage with minimal effort and cost are selected for concurrent error detection. Analysis of the experimental results about error coverage of different error detection mechanisms (Section 1.3) resulted in the conclusion that control flow and memory access checking can be used efficiently in microprocessor systems for concurrent, system level error detection. However, these techniques do not detect semantic or data manipulation errors. The detection of such errors is usually performed by coding or executing assertions.
Accordingly, a wide variety of watchdog processor methods are proposed by the literature to check the control flow, control signals, memory access behavior and reasonableness of results. In the following, these methods are surveyed. Control flow checking, as the most important mechanism is described in two separated sections. The application of watchdog processors in parallel system is outlined and the open problems are also discussed. At the end of the chapter our new Signature Encoded Instruction Stream (SEIS) method is presented.
Correct control flow is a fundamental part of the correct execution of computer programs. It is also a prerequisite for any software-implemented (system or application level) error detection technique, since disturbances in the control flow can disable the execution of such checks resulting in undetected errors.
The control flow of a program can be represented by a control flow graph (CFG). Nodes of the CFG represent some program units while edges represent the syntactically allowed flow of control. A node can be a single statement or a block of statements. Often also the program graph is defined in which each node represents a single instruction (at assembly level) or a single statement (in higher level languages).
In this work, the following notation is used: The application consists of processes running on a single or several processors. A process consists of procedures. In high level languages (C, Pascal etc.) a procedure is composed of statements. At assembly level, to emphasize the difference, he notation of instructions is used. Each procedure has its separate CFG.
All methods of control flow checking are based on assigning signatures (labels, tokens) to the nodes of the CFG. Before the program run, the WP is provided with the signatures labeling the nodes and the relationships among them given by the CFG (reference information). In run-time, the WP monitors the program run, computes the signatures concurrently (run-time information). The run-time signatures are compared to the reference ones provided earlier. If a discrepancy is detected then an error is signaled. In general, the structure of the control flow is checked, the details of the control flow related to execution semantics (such as data dependences) are not checked.
Many methods for control flow checking have been proposed. Almost in every year a new method or an improvement of an old one is published. As new processor architectures are introduced, the basic methods are regularly adapted. These methods differ from each other in the definition of a node, in the representation of the reference information and in the derivation of the run-time information. The following categories can be clearly distinguished:
The main difference between stored reference and reference program is that in the latter case the structure of the CFG is represented by the instruction sequence of the WP, i.e. the WP program performs a compiled graph tracing, which is faster and does not require a separate data structure.
On the basis of the error detection capability, the methods can check two properties of the control flow:
Assigned signature based methods check only the first property, since assigned signatures do not contain any information about the instructions of the node. The derived signature methods can check both. Table 2.1 gives a categorization of the typical methods discussed in the subsequent sections (Sections 2.2 and 2.3).

Table 2.1: Control flow checking methods
Memory access checking by watchdog processors [NM82] is based on the capability-based addressing scheme [Fab74]. Code or data address ranges in the memory are represented by objects. Each object has a capability (access right) for accessing another objects (e.g. read, write, execute). The set of objects and the corresponding capabilities are described as an object graph stored in the local memory of the WP in a tabular form. The WP monitors the physical memory accesses of the checked processor and derives the active object (from the address of the fetched instruction), the accessed object (from the destination address of the instruction) and the actual operation (analyzing the instruction itself). The access right required to perform the current operation is compared to the enabled access rights stored in the object table. If there is no match, an access error is signaled.
As it turns out, the scheme is similar to the common protection mechanism provided by memory management units of up-to-date microprocessors. Consequently, the technique has its grounds only in old-fashioned or (intentionally) simple systems without MMU.
The sequence of instructions executed by the processor is checked by control flow checking techniques introduced earlier. Similar techniques can be used to check the exact sequence of control signals corresponding to each opcode of a microprocessor. The scheme described in [Dan83] assigns a signature to each opcode by compacting the sequence of control signals using a multiple input LFSR. The reference signatures are stored in a ROM. When an opcode is fetched by the processor, it is also used to address the ROM. The reference signature is read and compared to the run-time one computed concurrently.
The method is proposed to check the (hardwired) control unit of the processor. Microprogrammed control units are intended to be monitored by the methods used for checking the control flow. However, the special techniques used in these units (e.g. horizontal microinstructions) often result in inadmissible overhead and performance degradation. To overcome these problems, modifications are aimed at extending the microinstructions inserting the necessary signatures in parallel [Nam82a], [ST82], [IK85]. Current research is focussed on the synthesis of self-checking state machines and control units by different techniques (see Section 2.5).
Data errors can be detected by having the watchdog execute assertions concurrently. An assertion, as a notion of program correctness [Flo67], is an invariant relationship between the variables of a program. It is inserted by the programmer at different points in the program, signifying what he thinks (or intends) to be true for the variables. Assertions can be written on the basis of the specification or some property of the algorithm (inverse of the problem, range of variables, relationships).
The use of assertions for detecting software and hardware faults is proposed in [And79] and [MMA84]. The effectiveness was demonstrated by measurements in [AB81]. The designs proposed for executing assertions are sophisticated and complex, because they are aimed at not only detect errors but also recover the last verified state (e.g. recovery caches, [LS84]).
The application of watchdog processors for the concurrent execution of assertions is proposed only for error detection. The main objectives of the design is to keep the complexity of the WP as low as possible and to transfer the data from the main processor to the WP without significant overhead. There are two alternatives to solve these problems. In both schemes, the code of the assertions is stored in the local memory of the watchdog as a library of functions. Only identifier of the assertion function and the data have to be transferred to the WP.
If the WP checks particular applications in which the flow of data (the sequence of data values on the data bus) is known and invariant then the WP is able to capture the data by monitoring the data bus of the checked processor (instructions accessing the data can be tagged). Such special purpose watchdog processors [MML83] are proposed for telephone switching systems or digital flight control systems.
If the WP is a general purpose one then the transfer of data can be organized by shared memory or a message queue. The first solution needs complicated synchronization techniques. The second one is discussed in [MEM85]. Before execution, the program is modified by replacing the assertion functions with a single statement which transfers the data values and the identifier of the function to the WP. Additionally, the code of the assertion functions is downloaded into the local memory of the WP. In run-time, the WP receives the data and executes the required function. If the logical statement represented by the assertion function is false then an error is signaled.
The execution of the assertions needs a complex WP architecture, usually a general purpose microprocessor is required. Special purpose RISC processors with hardware support for fast comparisons and range checking were proposed in [MM88]. However, in most of the cases the replication of the main processor is a reasonable alternative.
Derived signature based methods share the same principle: the WP compacts the instructions executed by the checked processor, and periodically compares the (intermediate) results of the compaction, which are the signatures, to pre-computed references. In other words, the nodes of the CFG are labeled by signatures that represent the instructions corresponding to the node. The WP computes the signatures in run-time concurrently and compares it to the reference information provided earlier.
The first schemes were introduced in 1982 ([Nam82b] and [ST82]) followed by a number of improvements and modifications (e.g. [Nam83], [SS83], [ES84], [SS87], [ST87], [WS90a], [Sos89], [MLS91], [DS91]). The methods differ in the definition of the node and in the representation of the reference information. Different processor architectures (traditional CISC, RISC with pipeline) and configurations (mono-, multiprocessors) are targeted, the authors try to find a compromise between the error coverage and the complexity (overhead) of the checking.
In the first method Basic Path Signature Analysis (BPSA, [Nam82b]) a node is defined as a branch-free sequence of assembly level instructions, the reference information is given by embedded signatures: the reference signature is inserted at the beginning of each node. The WP monitors the instruction bus of the processor and captures the reference signatures, using tag bits to differentiate them from the normal instructions. (The main processor executes a NOP instruction whenever a signature is fetched.) For the normal instructions, the WP computes the run-time signature concurrently. At the end of the node (signaled by a second tag bit) the run-time signature is compared to the reference one. Any discrepancy is taken as an indication of error.
The first modifications aimed at to improve the following properties of BPSA (still using embedded reference signatures):
The Watchdog Assist (WA+EPC, [SM89]) method defines the reference signature as the extended precision (check)sum of the instructions belonging to the instruction block of a node. The reference is transferred at the beginning of a block, and the codes of the run-time instructions are subtracted. At the end of the block, the all-zero result is checked. The method provides the capability of a WDT without requiring a separate WDT unit: an error is detected if the result becomes negative before a zero check signal. (The transmission of the reference and the zero check signal are implemented by coprocessor instructions.)
The first method Generalized Path Signature Analysis (GPSA [Nam82b]) reduces the total number of signatures by checking paths rather than simple nodes. The CFG is divided into path sets, each set includes paths starting from the same node. Since there is only one reference signature for each path set, the run-time signature of each path in a set must be the same. It is assured by inserting justifying signatures in some paths. These signatures are involved in the computation of the run-time signature, so that the same signature results at the end of each path. (The justifying signatures can be computed if the inverse of the function used to compute the run-time signatures exists.)
The second method Branch Address Hashing (BAH, [SS83]) can reduce the overhead for storing signatures by 50%. The nodes are defined differently and the reference signatures are inserted at the end of the node. In default case (BPSA), each branch instruction should be preceded by a signature. In BAH, instead of embedding the signature, the branch address of the instruction is modified at assembly time in such a way that during execution, the (changed) branch address combined with the run-time signature results in the branch address taken actually by the processor. In the case of an error, the run-time signature and consequently the branch address are incorrect, resulting in a jump to an erroneous destination. The error is detected when the next reference signature is encountered (and the actual run-time signature is checked). In the method, an explicit reference has to be inserted preceding each branch-in point. In error-free case, the run-time signature is all-zeros, making the comparison easier.
In complex CISC processors where the instructions have various execution times and utilize different resources of the processor, the optimal placement of signature transfer and check instructions can reduce the overhead in itself [Wil91], [Wil93].
The Universal Signature Monitor (USM [Sos89], [Sos88b], [Sos88a]) uses path tags to check the validity of the sequence of nodes (in each node a path tag is assigned which is checked at the beginning of the next node) and block signatures to check that the block is started at its entry point (block signatures are checked at the end of the block). This way a higher error coverage is obtained.
A similar method is the Implicit Signature Checking [OR95] which assigns unique signatures to each basic block by using the block's start address, this way obtaining implicit signature checking point at the beginning of each block. Justifying signatures are embedded at each branch instruction.
The overhead caused by the embedded reference signatures can be completely eliminated if the reference information is moved to the environment of the WP. Moreover, it is possible to verify existing programs without re-compilation. Two categories are distinguished:
In the Checker of [MCS91], the reference signatures are stored in associative memory segments. The checking of the run-time signatures is fast (examining whether they are included in the reference signature database), but the complexity of the WP is high (see also in Section 2.4).
A similar method is introduced in [MLS91], the Watchdog Direct Processing. The program of the main processor can be checked without its modification. Control flow checking is achieved by direct address monitoring and a shadow watchdog program, instruction bit error checking is solved by an instruction compacting device. Due to the more detailed checking (branch address hashing, immediate address break detection etc.), the error coverage and latency is reported to be better than that of the Cerberus-16.
In the derived signatures methods, run-time signatures can only be computed if the sequence of instructions executed by the checked processor can be captured by the WP. In the case of traditional processor architectures, it can be solved easily by monitoring the instruction bus of the checked processor. The sequence of instructions fetched by the processor is exactly the sequence executed by it. However, up-to-date processor architectures (e.g. Intel i486, Pentium [Cor94]), include on-chip instruction cache and prefetch queue (pipeline). The sequence of instructions fetched by the processor can still be monitored by the WP but it is not exactly the sequence of instructions executed by the processor. Some instructions are executed in different order or are not executed at all.
The problem of monitoring pipelined RISC processors was solved in [DS91]. The main idea was that the reference signatures were computed on the basis of the instruction sequence fetched by the main processor, and the basic functions of the pipeline were imitated in the WP. The two events, which make a classical signature inconsistent are handled by some new notions. Delayed branching is resolved by anticipated signatures, i.e. always taking into account in the compaction (and in the computation of the reference) the delayed instructions following a branch, independently of the fact that they are executed or not. Exceptions and the corresponding flush of the pipeline are handled by delayed signatures, i.e. an instruction code is compacted only if a given number of successors are regularly fetched.
The other problem, the derived signature-based monitoring of processors with built-in cache remained unsolved. An external observer can not guess the instructions fetched by the processor from its cache, and the integration of the WP into the processor core can not be performed in off-the-shelf, commercial systems. The problem can be solved by assigned signatures methods, having the processor explicitly send the signatures to the WP. If the external signature transfer (i.e. not into the built-in cache) is not too slow compared to the operation of the cache then the performance degradation remains at an acceptable level.
Assigned signature control flow checking methods label the nodes of the CFG with signatures and check that the run-time sequence of signatures is allowed. Early methods checked the sequence by recording the execution and comparing it with sequences determined during programming or testing [KY75]. In an other method, points in the sequence were assigned with distinct prime numbers and compressed by multiplication into a check symbol [YC80]. At the end of the run, the run-time labels (primes) could be decomposed and checked.
Structural Integrity Checking (SIC [Lu82]) was the first method which resulted in a much simpler implementation by making use of the control structure embedded in the syntax of the programming language. It introduced the typical software configuration used then in all assigned signatures methods (Figure 2.1).
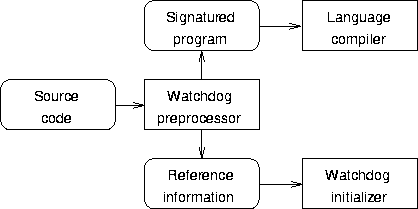
Figure 2.1: Software configuration of assigned signatures methods
The preprocessor is a program that reads the source of the checked program and assigns the signatures to the nodes of the CFG. It works in four steps:
The particular assigned signatures methods differ in the way how the signatures are assigned to the nodes (Step 2) and how the reference information is represented (Step 4). These decisions determine also the checker structure.
In SIC [Lu82], the nodes are encoded by selecting 8 bit numbers randomly and independently from a uniform distribution (to minimize the chance of a random transfer to a statement with the same label as the correct instruction, and to assign label values so that sequences of labels are likely to be distinct). The reference information is represented in the form of a reference program which has the same CFG as the checked program. In place of computations, it contains statements to receive and check the signatures from the main processor. The computational requirements of the WP are less than those of the main processor, however, since the reference program is extracted in the same language, the implementation requires a processor of the same type or a specialized compiler.
The ideal SIC method is defined in terms of two automata, one representing the checked program and a second one representing the execution of the reference program. The signature sequences of the checked program are described by a context-free grammar. The checker, as a push-down automaton, accepts the sequences described by the context-free grammar and rejects any others. (In some cases, it is possible to use an equivalent regular grammar, which reduces the function of the checker to a finite automaton.)
Extended Structural Integrity Checking (ESIC, [MH91], [Mic92]) extended the checking capabilities of the SIC to check run-time computed (data-driven) procedure calls and interrupt handlers. The nodes of the CFG are encoded by successive numbers, the reference information is extracted in the form of stored reference (signature database, the valid successors of each signature are given in a sparse matrix format). The first and last nodes of a procedure are tagged by special flags: SOP (Start of Procedure) and EOP (End of Procedure).
The operation of the WP can be described as a finite deterministic stack automaton. States of the automaton are associated with the nodes of the checked CFG, the next state is determined by a valid run-time signature. Invalid signatures are detected and the corresponding error is signaled. If a SOP signature is received (procedure call) then the actual state (pointer to the previous signature) is pushed to a WP-internal stack and the initial state corresponding to the called procedure is reached (i.e. the reference information of the called procedure is accessed). After an EOP signature (return from a procedure call) the original state (pointer to the original reference signature) is popped from the stack.
Since SOP signatures are allowed at any point of the signature sequence, procedure calls which are nondeterministic in the preprocessing phase (called by variables) as well as interrupt handler procedures can be checked. It remains unchecked whether the correct procedure is called, but the return address is checked using the signature stack.
The advantages of the assigned signature based methods are the relatively easy implementation of the preprocessor and the ability of asynchronous checking. The disadvantages can be summarized in four points:
An interesting, but very processor-specific technique is proposed in [SS91]. The main processor itself emulates the signature checker by utilizing unused resources. A similar technique is to implement a WP process which fits entirely in the instruction cache memory of the main processor [DM90].
An additional disadvantage of the mentioned two methods arises if we take into account that the execution of the reference program and the search and compare engine in the stored reference needs a sophisticated WP implementation comparable in cost and complexity with the checked processor.
Parallel system are commonly categorized as multi-computers or multi-processors. Multi-processors make use of a global shared memory and a conventional programming model. Multi-computers, further categorized as distributed systems, workstation clusters or massively parallel multi-computers, are scalable, consisting or loosely coupled, high performance computing nodes and clusters. In both main categories, concurrent error detection (as part of the fault tolerant operation of the system) is a critical factor due to (i) the high number of components, (ii) the rapid spread of errors by communication between the components and (iii) the long computing time of the applications.
From the point of view of error detection, there are a few differences between multi-computers and multi-processors [CP94]. In multi-computers, error detection can be provided by mono-processor techniques which can be easily integrated into the computing nodes. Since error propagation is constrained to erroneous messages, it can be prevented by robust protocols and reasonableness checks. In multi-processors, as state is shared by the processors and communication is not restricted to messages, the application of mono-processor techniques is often no longer satisfactory.
WP methods are traditionally developed for mono-processors, checking the computing core, which is the most intensively used resource and typically a core in checking the other system components. The extension of the mono-processor solution to multi-computers or multi-processors always requires the sharing of the WP among multiple nodes (processors), to keep the hardware overhead at an acceptable level. The number of nodes checked by a single WP is limited by the speed of the interface and of the processing in the WP.
Several WP methods are proposed to check parallel systems by using shared watchdog processors ([ST87], [MCS91], [MH91]). Since they do not check the interactions between the nodes, they are referred to as WPs in multiple processor systems.
The already introduced Roving Monitoring Processor (RMP, [ST87]) is based on the asynchronous signature checking method ASIS [ES84]. There is a hardware signature generator and a corresponding signature queue (FIFO memory) for each application processor. The RMP samples the queues and checks that the signature sequence corresponds with the stored reference CFG. The different processors are identified by a processor ID (used by the RMP to switch to the reference CFG of the actual processor). A prototype of RMP was able to monitor 16 processors (the speed of the checking was high, 300ns/signature, and the the peak signature transfer rates were equalized by the queues).
A similar, shared WP is proposed in [MCS91]. The derived signatures are generated by hardware generators (including address break and interrupt detectors) attached to the application processors. The reference signatures are downloaded into the WP (called here the Checker) before the program run. Based on the address of the last instruction corresponding to a signature, a program segment identifier is derived for each run-time signature, in such a way, that each segment contains a given (small constant) number of signatures. For each segment of the program there is a corresponding section of the Checker memory where the allowed signatures are stored. A run-time signature is considered correct if it is present among the ones stored in this section. The verification is done by using fast associative search. The main advantages are that (i) the overhead of the reference memory is reduced since the structural information is not stored and (ii) the associative search is fast enough to serve several processors in a fashion similar to the above roving concept.
The assigned signature based ESIC WP [MH91] is implemented utilizing the advantageous properties of a transputer. Each application process is checked by an independent WP process. The signatures include process ID fields which control the fast context switch between these checker processes. The serial links of the transputer can be used to communicate between several WPs in a multiprocessor and to send reports and status information to a supervisory system. However, the possible co-operation of the WPs is not elaborated yet.
The main problem of the proposed methods originates in the fact that they use stored signature reference. The memory overhead (size of the reference) increases (over)proportionally if more processes or computing nodes are added, and the start of a new process always requires the time-consuming download of the corresponding reference database. Note that in a common uniprocessor Unix system several hundred processes can run simultaneously. Additionally, the complexity of the control section of the checker is still considerably high (list, database or associative search).
It is worth to mention that a WP-assisted recovery algorithm of distributed systems is proposed in [RU95] (also an uniprocessor based rollback technique in [US86]) which utilizes the low latency error detection of a WP to develop a message validation technique which helps in reducing the excessive rollback during recovery. However, beyond the error detection, the WP plays no further role in the technique.
The measurement results (overhead, error coverage, error latency) of the mentioned various methods are found in the corresponding literature. Here an overview is presented in Table 2.2 which includes the typical values.

Table 2.2: Measures of control flow checking methods
The analysis of the values in Table 2.2 results in the overall conclusions that derived signature based methods have better measures than assigned signatures methods. However, their main drawback is that processors with built-in cache can not be checked at all. Assigned signatures methods have less error coverage, higher error latency (with high variance) and high overhead, but they can check all well-known processor architectures.
The drawbacks of the assigned signatures methods are solved by a nre
method called SEIS (Signature Encoded Instruction Stream,
[MPC ![]() 94]). The hardware overhead is reduced by the elimination
of the reference database and by the simplification of the checker
architecture. Embedded reference is used, the reference signatures
are transferred to the WP in parallel with the run-time ones (thus
keeping the number of signature transfer instructions at the same
level). The reduction of the reference database allows the WP to be
used in multitasking, multiprocessing systems. To increase the error
coverage, the assigned signature based control flow checking has been
extended (in multiprocessing systems) to some still uncovered areas
like scheduling, synchronization and cooperation of processes.
94]). The hardware overhead is reduced by the elimination
of the reference database and by the simplification of the checker
architecture. Embedded reference is used, the reference signatures
are transferred to the WP in parallel with the run-time ones (thus
keeping the number of signature transfer instructions at the same
level). The reduction of the reference database allows the WP to be
used in multitasking, multiprocessing systems. To increase the error
coverage, the assigned signature based control flow checking has been
extended (in multiprocessing systems) to some still uncovered areas
like scheduling, synchronization and cooperation of processes.
It is worth to mention that the elimination of the reference database is a well-known problem in the synthesis of self-checking finite state machines (FSM). The states of the FSM have to be encoded in such a way that the state transitions can be checked by an (on-chip) checker. Numerous papers describe various checker architectures and encoding techniques (e.g. using convolutional codes [HK91], signature analyzers [LS89] or other forms of self-monitoring [Rob92], [RS92]). However, these methods require the modification of the original CFG. This is allowed in FSM synthesis since both state splitting and insertion of new states are possible. However, the CFG of a high-level program can not be modified in a similar way: state splitting and modification of the original control structures by inserting new states (nodes) is in general impossible.
One of the joint research projects of the Department of Measurement and Instrument Engineering (Technical University of Budapest) and the Department of Informatics III (University of Erlangen) was the development of a high-speed watchdog processor. The goals and guidelines of the project were as follows:
In the following first the basics of the signature assignment are discussed, then the SEIS algorithm for computing of the signatures is outlined. The checking of the procedure calls is presented in the next section. Support of error recovery and the hardware architecture of the WP are also described. At the end, measurement results and conclusions are presented.
In the assigned signature method the only requirement for the labelling of instructions with signatures is their uniqueness for identifying the main program location. The main idea in the new method called Signature Encoded Instruction Stream (SEIS) is a different encoding algorithm of the CFG signatures, so that each signature uniquely identifies its successors as well, similarly to the fault-tolerant hardware implementation of finite state machines. In this way only the last signature in each subgraph is to be stored in the WDP, as the check of the signature sequence requires only the combinational comparison of the actual signature and the successor fields in the previous signature. The program or automaton table handling in the previous methods can be omitted, reducing both hardware and time complexity of the WDP. Subroutine calls can be handled in an identical way as in ESIC.
A main difference to the finite state machine synthesis with an unlimited number of potential successors and predecessors of a state is, that in a CFG this number is very small for the overwhelming majority of instructions. Accordingly, when limiting the number of successors to a value k, a vertex can be identified by the concatenated labels of its successors. In the case of multidirectional control transfer instructions violating this assumption, like a CASE statement, intermediate vertices are to be inserted into the CFG. This results in only a moderate time overhead, since the majority of control instructions has only 2 successors. In our implementation k=3 was chosen.
If we order the codes used for labelling and encode the vertices on a directed path in the CFG with subsequent codes (further referred to as sublabels), then the execution of the instruction sequence corresponding to this path will produce an easy-to-check sublabel stream consisting of subsequent codes. A vertex can belong to multiple paths, and accordingly, multiple (maximally k) sublabels can be assigned to it. As signature their concatenation is used. If a vertex is traversed by less than k paths, then a dummy sublabel is assigned to the remaining part of the signature in order to have a fixed-length encoding. During program execution the WDP has only to check whether some sublabel in the current signature is a successor of a sublabel in the previous one.
The input of the SEIS preprocessor is the original high-level program source, the output is the modified program text which contains the inserted statements which transfer the run-time signatures to the WP. The preprocessed program can be compiled by the original compiler of the language and it can be executed without further modifications.
The steps of the SEIS encoding algorithm are presented informally as follows:
This encoding method defines the checking rule as well: A signature is a valid successor of a reference one if and only if one of its sublabels is successor (in the used cyclic ordering of the sublabel codes) of one of the sublabels of the reference signature.
The SEIS graph extraction and encoding algorithm assures that if programs in C language are preprocessed then the number of sublabels of each vertex is limited by 3. The edges which are encoded using less than 3 sublabels are completed appending one of the existing sublabels to the signature once again. The fact that each signature consists of a fixed number of sublabels enables a simple implementation of the WP hardware. The base of the signature evaluation is the rule described in Step 3.
As an example consider the following procedure:
int test_procedure()
{
for (f=0; f<9; f++) {
if (a<b) a=b+f;
else c=a-f;
}
}
The preprocessed version of this procedure is as follows:
int test_procedure()
{
SENDSIG(SOP,1,10,1); {
for (f=0; f<9; f++) {
SENDSIG(NRM,2,5,2); {
if (a>b) {SENDSIG(NRM,3,3,3); a=b+f;}
else {SENDSIG(NRM,6,6,6); c=a-f;}
SENDSIG(NRM,4,7,4);}
}}
SENDSIG(EOP,8,11,8);
}
The SENDSIG macro transfers the signature to the watchdog, its implementation depends on the hardware interface between the checked processor and the watchdog. The parameters of the macro are the signature type (see later) and the sublabel codes. The signatures belonging to adjacent statements contain subsequent sublabel codes, in this example the successor function is the one which increases the code by one.
There are two ways to check the procedure calls. First, intermediate signatures can be inserted before and after the procedure calls connecting the first and last signature of the called procedure to the reference of the caller environment. In this way the caller and the called procedures have a single common CFG.
The second method allows the use of independent CFGs of the called procedures. In the WP, similarly to the checked program, a signature stack is implemented which stores the reference signatures of the embedded procedure calls. The initial and final vertices of the procedures are marked by Start of Procedure (SOP) and End of Procedure (EOP) flags. Receiving a SOP signature the watchdog stores the actual reference signature on the stack (signature push), the first reference of the new CFG is the actual and unchecked SOP signature. In the case of an EOP signature the most recently saved reference is restored from the stack (signature pop operation) and checking of the CFG of the caller procedure resumes.
The scheduler can be checked by appending a process identifier to each signature. Changing the running process the scheduler transfers the ID of the actual process to the watchdog. The WP stores it internally and compares with the identifiers embedded in run-time signatures. Only the signatures of the actual running process are valid.
Synchronization of processes can be checked by using guard signatures. They are transferred to the WP in the same way as the normal signatures, but their effect and evaluation are different. Two type of guards are used: initialization guard, inserted before a communication statement, and checker guard, inserted after it. The processes beginning a synchronization initialize the communication registers in the WP by the initial guards. Receiving a checker guard, it is evaluated in the WP fault-free if all the processes which are partners in the synchronization have already sent their initialization guards.
If an error of a checked process is detected then the system is interrupted and a status word is available in the WP which contains the detailed description of the error. The system can restart the execution of the erroneous process (rollback recovery) using a previously saved state, which is called a checkpoint.
The SEIS WP supports the rollback recovery of the checked system. When the main processor stores a checkpoint then simultaneously the state of the actual process is saved internally in the WP (initiated by a special command similar to the guard signatures). The WP-internal state of a process is its signature stack, so it has to be stored as checkpoint. If a rollback recovery is performed then the checkpoint stack domain replaces the actual one, in this way the execution as well as the checking of the process can continue from a fault-free previous state.
The signatures assigned to the processes of a multitasking application consist of 5 parts: the 3 sublabels, the procedure and the process identification numbers (the use of procedure ID is optionally; in multiprocessor systems processor ID can be used as well). These parts are evaluated by autonomous modules of the WP hardware:
An experimental implementation of the SEIS WP was built using standard programmable logic devices (MACH series of AMD). The procedure stack was implemented in a 256K RAM which was shared dynamically between the processes (this stack proved to be oversized if no recursive procedure calls were checked). The WP as a coprocessor on the 32 bit VME bus can check multiple processors in a time-sharing manner. The transfer and evaluation of a signature takes about 500 ns.
The first measurements have shown that there is a strong dependence between the fault coverage and the number of signatures sent to the WP (the time and memory overhead of the preprocessed program).
The memory overhead is acceptable even for programs in the MB range (in average up to 30%). However, the time overhead is a critical factor. If the signature transfer needs more time than the fetch and execution of a processor instruction, then the overhead can exceed 100%, especially in applications consisting of small iteration loops (in each step a signature has to be transferred). To reduce the time overhead, two reduction algorithms were elaborated. The first one, static reduction, reduces the number of signatures eliminating vertices in the CFG. The second one, called dynamic reduction, decreases the overhead caused by the overtested short loops. Signatures are not transferred in each execution of the loop, only at a given rate. Both reduction algorithms are controlled by user-defined reduction factors.
Fault injection experiments were executed with different static and dynamic reduction factors. Without any reduction, the WP is able to detect up to 50-60% of the errors not detected by the standard error detection mechanisms of the system (e.g. access to non-existent or unused memory, segmentation fault, illegal opcode). Using static reduction, the fault coverage decreases rapidly, as the time between subsequent signatures increases (especially in high-level programs where the statements can cover complex instruction sequences at the assembly level). Dynamic reduction of small factors has no such disadvantageous effects; while reducing the time overhead, the fault coverage remains similar as without reduction.